
CCIX and Real-World Application
At Arm TechCon 2019 and SC19, CCIX Consortium members demonstrated the advantages of using CCIX’s seamless acceleration capabilities for in-memory database applications like Redis and MongoDB. While still a proof of concept, this real-world use case offers a great insight into how these types of applications can benefit from CCIX.
First, a bit of background about the technology. The demo used the Arm Neoverse N1 system development platform which uses the Arm N1 CPU design. The N1 CPU provides hyperscale performance for server applications, as well as Edge, 5G wireless, and smart network devices. The Xilinx Alveo U280 Datacenter Accelerator card offers 8GB of HBM2 with 460 GB/s of bandwidth and is designed to provide high-performance, adaptable acceleration for memory-bound, compute intensive applications.
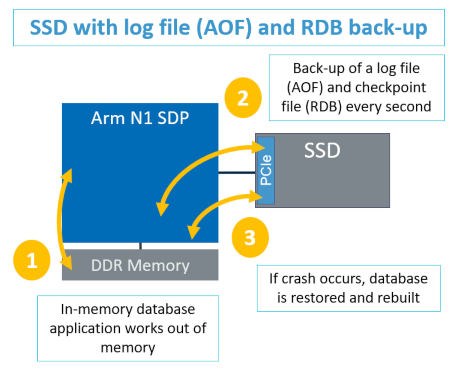
With that in mind, we need to understand the real-world challenges. Whether using Redis or MongoDB databases, all such in-memory type databases periodically need to write to a persistent, non-volatile memory so as not to lose changes to data if power fails or another unforeseen circumstances happen. By default Redis backs up the in-memory database every second, creating a back-up of a log file (AOF) and checkpoint file (RDB) every second. (Fig. 1). This requires file system overhead to write those files to the memories or to the SSD or hard disk drive every second. While this helps eliminate data loss due to a system error, this data backup path can be slow and wastes valuable CPU cycles.
In the demo, the Xilinx Alveo U280 was connected to an Arm Neoverse N1 Platform via the CCIX protocol. The CCIX protocol maps the memory that resides on the U280 directly into the NUMA memory map of the Arm N1 host in a cache coherent manner. This provides a shared virtual memory across the entire system, while at the same time allowing the application to speed up the transfer of data using the CCIX link. This permits the database to run directly off of the memory that is attached within the FPGA. (Fig. 2) In instances where the system is using persistent memory, all database reads and writes can happen via CCIX through the FPGA to the persistent memory.
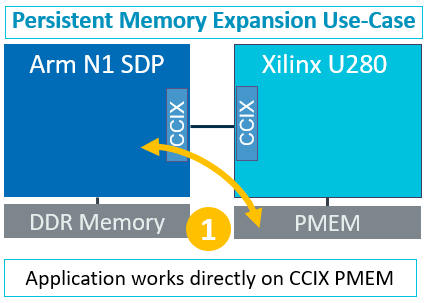
Allowing the read/writes directly to the FPGA eliminates the processing for file system overhead and can boost performance 2x over backing up data to a solid state NVMe drive. In addition, tasks like file system metadata management can be accelerated in the FPGA, further reducing the number of compute cycles needed to write Redis or MongoDB databases to persistent memory.
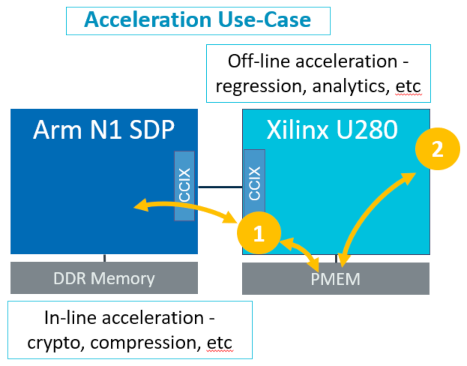
With the CCIX link established between the FPGA and the host, additional custom acceleration functions can be offloaded to the FPGA, freeing critical CPU cycles (Fig. 3). Implementing an acceleration function on the FPGA with a Cache and a Request Agent enables functions such as in-line compression and decompression of the database or the off-line addition of a module that runs directly on the accelerator without any impact to the host.
These are just a few use cases where CCIX continues to deliver on its initial goal of providing seamless cache coherent acceleration. As more members products come to market, we look forward to highlighting more real-world use cases that further demonstrate how applications continue to benefit from CCIX’s capabilities.