The Memory Expansion Benefits Of The CCIX Standard
One of the primary benefits of the Cache Coherent Interconnect for Accelerators (CCIX) standard is that it makes accelerator cards peers to processors by virtue of the CCIX protocol’s coherency feature. This means the accelerator function has the same view of the data as the processor. Moving data to a cache of an accelerator function provides low latency access to data that is repeatedly being accessed by the accelerator function. Overall this provides an excellent framework for applications which have a fine grain data sharing model between an application on a host, like packet processing, graph search algorithms, key-value store databases etc., and an accelerator function on an acceleration add-in card connected to the host.
There are many ways an accelerator with a CCIX interconnect can be used to create a better solution than what can be created today. For example, the memory expansion capability enabled by CCIX allows Storage Class memory (SCM) to have a significantly lower cost solution with much larger storage capacity. Moving the SCM to an add-in card connected via CCIX allows for just the right type and amount of SCM to be delivered. Storage engine acceleration (for example WiredTiger in MongoDB) with compute and partial file system offload can be implemented using CCIX, allowing actual file data to be stored into SCM connected to an FPGA that contains an application accelerator, while critical file operations like read and write can be offloaded to the accelerator via CCIX.
Additionally, database applications that use key value store, like Memcached and Redis for example, will see significantly increased performance by offloading processing of more frequently used queries like “get” operations in Memcached.
For offloading “get” operations to the accelerator there are two strategies that can be used for sharing of the meta-data structures like contention data-structures and the hash tables for mapping keys to the index of values. The first way is to have the meta-data in the host memory and the accelerator function (AF) access the host memory through a local cache for linked list traversal. (Figure 1) When the cache is local to the accelerator the offloaded function significantly reduces latency for data in the cache. CCIX enables this approach utilizing a CCIX Request Agent (RA) on the accelerator. Any change to a linked list structure already cached in the accelerator would invalidate that entry and the CCIX protocol would fetch the correct data, thereby ensuring that the accelerator function always has the most up to date data. The CCIX protocol can do all this seamlessly without any additional software instruction.
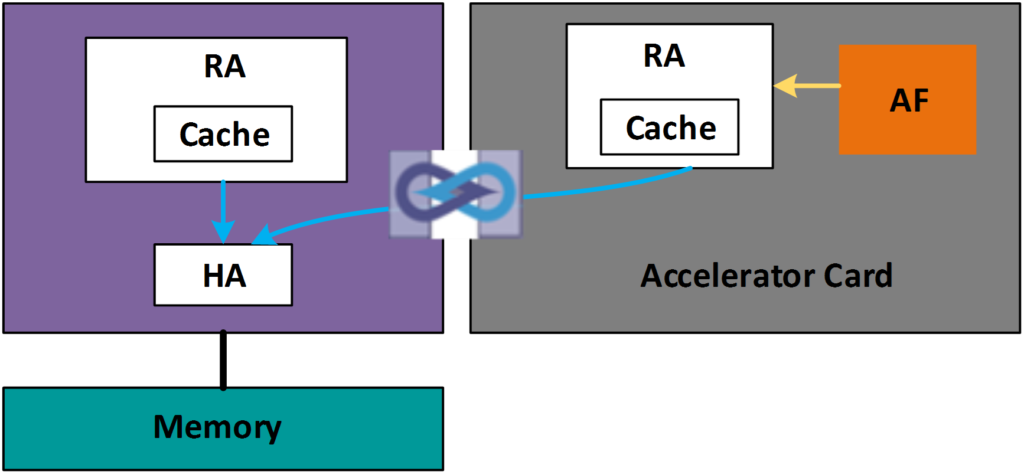
Figure 1: Accelerator sharing processor memory
A second way to improve the acceleration function efficiency is by enabling the CCIX Home Agent (HA) along with the CCIX Request Agent (RA) on the accelerator. Figure 2 shows how data can be stored in the extended memory of the accelerator via CCIX-HA exposed memory. The processing paradigm for the accelerator function now shifts to near data processing (NDP) i.e. moving the processing closer to data. This benefits both latency and bandwidth and enables the use of High Bandwidth Memory (HBM) or DDR4 available to the accelerator. Having a Home Agent that resides on the Accelerator Card can only be enabled with a protocol that is balanced. Other cache coherent protocols that are not unbalanced cannot implement this structure.
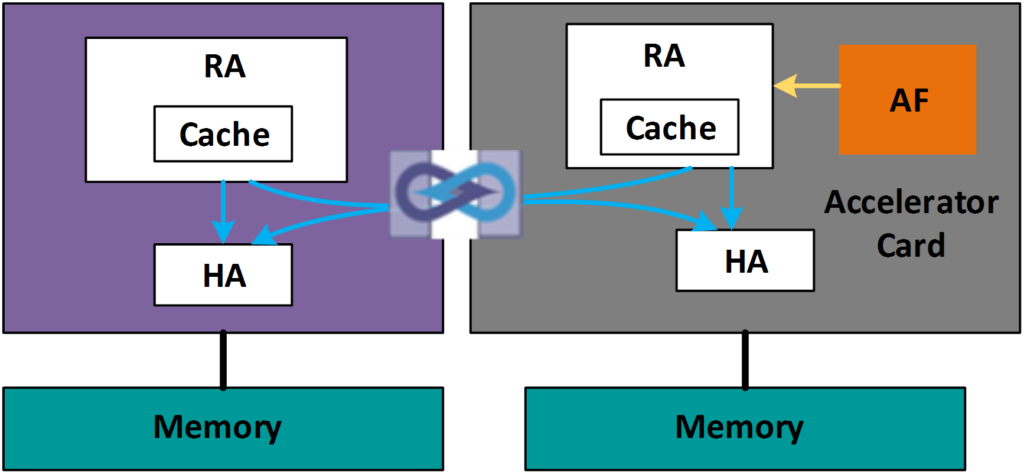
Figure 2: Near Data Processing with shared memory
The capability to support both CCIX-HA and CCIX-RA modes remains an important differentiator, enabling accelerator functionality to take advantage of an array of signal processing cores as compute augmentation for a host. Just as importantly, CCIX Consortium members continue to demonstrate the versatility of the CCIX standard and HA/RA support with silicon that is currently shipping. For example, Xilinx’s new Versal™ devices, the industry’s first adaptive compute acceleration platforms (ACAP), offer support for two CCIX ports operating at speeds up to 25GT/s with link widths up to x8*.
Finally, as new and unique types of memory become available in the ecosystem, having a way to easily integrate these new memories with minimal cost and disruption can breathe new life into aging systems. CCIX enables the introduction of this new memory via memory expansion into existing NUMA (Non-uniform memory access) paradigm without any disruptive change to the existing software stack. This enables large capacity memory to be connected as shared memory between host and accelerator function residing on the accelerator card. Whether the memory is something unique like persistent memory or something new that has not even been thought of yet, CCIX’s memory expansion feature makes integrating this memory easier than ever before.
As the industry continues to look to accelerators to provide applications with greater bandwidth and lower latency than a CPU alone, CCIX’s ability to seamlessly provide memory expansion capabilities – without additional software instructions – will allow system designers to increase system performance by enabling the processor and the accelerator to share cache through the unique use of the Home Agent on the accelerator.
*More information about Xilinx’s Versal devices can be found at www.xilinx.com/versal.